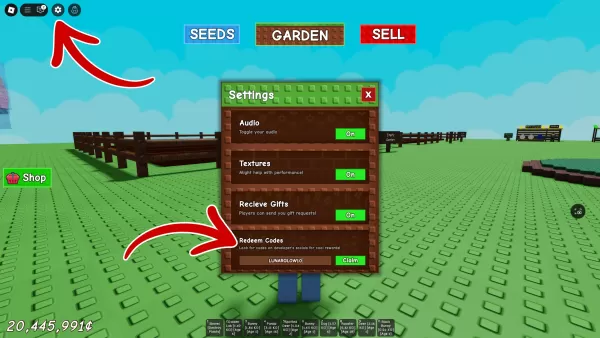
DeepSeek令人惊讶的负担得起的AI模型挑战了行业巨头。这家中国初创公司声称已经培训了其强大的DeepSeek V3神经网络,仅利用2048 GPU,这与竞争对手的成本明显更高。但是,这个看似低的数字省略了研究,改进,数据处理和基础设施等大量费用。
DeepSeek的创新方法利用了几种关键技术:多型预测(MTP),以提高准确性和效率;专家(MOE)与256个神经网络的混合物,用于加速培训和表现;以及多头潜在注意力(MLA),专注于关键句子元素。
 图像:ensigame.com
图像:ensigame.com
与DeepSeek的公开数字相反,半分析揭示了涉及大约50,000个NVIDIA HOPPER GPU的大规模计算基础设施,包括H800,H100和H20单位,分布在多个数据中心。服务器总投资估计为16亿美元,运营成本达到9.44亿美元。
 图像:ensigame.com
图像:ensigame.com
高飞行员对冲基金的子公司DeepSeek拥有其数据中心,与云规范的竞争对手不同,授予其更大的控制和更快的创新实施。它的自筹资金地位有助于敏捷性和快速决策。该公司吸引了顶尖人才,一些研究人员每年收入超过130万美元,主要来自中国大学。
 图像:ensigame.com
图像:ensigame.com
尽管DeepSeek的600万美元培训成本索赔具有误导性,但其总投资超过5亿美元。它的精益结构可实现有效的创新部署,与更大,更官僚的公司形成鲜明对比。该公司的成功取决于大量投资,技术进步和熟练的团队。
 图像:ensigame.com
图像:ensigame.com
DeepSeek的故事展示了一家资金充足的独立AI公司,成功与行业领导者竞争。但是,鉴于总体投资,革命性成本效益的叙述需要细微的理解。不过,这种对比仍然很明显:DeepSeek的R1型号的训练费用为500万美元,而Chatgpt4的1亿美元。尽管有澄清的费用,但DeepSeek的效率仍然对既定订单提出了引人注目的挑战。
-
 灵感源自《霍斯家族》的街机风格赛车游戏 - 提供单人比赛、锦标赛、计时赛和本地多人模式供你选择 - 收集、升级并自定义16辆汽车,驰骋于12条赛道之上 如果你曾希望手机里能装下一点点“霍斯家族”式的狂野气息,《Junkyard Rush Racing》随时准备满足你的期待。这款粗犷的街机赛车游戏将你带入尘土飞扬的乡间土路、锈迹斑斑的汽车废料场以及蜿蜒曲折的乡村公路,空气中弥漫着浓重的沙尘味,对手们毫不留情。从疾驰的车辆到喧闹刺激的赛道,周围的一切都在为混乱而生。 《Junkyard Rush作者 : Aiden Apr 22,2026
灵感源自《霍斯家族》的街机风格赛车游戏 - 提供单人比赛、锦标赛、计时赛和本地多人模式供你选择 - 收集、升级并自定义16辆汽车,驰骋于12条赛道之上 如果你曾希望手机里能装下一点点“霍斯家族”式的狂野气息,《Junkyard Rush Racing》随时准备满足你的期待。这款粗犷的街机赛车游戏将你带入尘土飞扬的乡间土路、锈迹斑斑的汽车废料场以及蜿蜒曲折的乡村公路,空气中弥漫着浓重的沙尘味,对手们毫不留情。从疾驰的车辆到喧闹刺激的赛道,周围的一切都在为混乱而生。 《Junkyard Rush作者 : Aiden Apr 22,2026 -
 Soul Strike X:泽尼亚第二季是一款高奇幻动作角色扮演游戏,战斗围绕精确的时机把握和强大的技能组合展开。鉴于各种角色和构建拥有大量可用的能力,识别表现最佳的技能对于成功至关重要。这些知识是征服 PvE 内容、击败挑战性首领以及在竞技 PvP 中攀升排名的关键。该游戏巧妙地将激烈的砍杀动作与深度的 RPG 机制及广泛的技能自定义相结合。无论你的目标是推进困难副本还是主宰 PvP 排行榜,这份梯队列表都将指导你的升级决策,以优化伤害输出和整体效能。此外,角色、同伴与宠物之间的协同作用能显著作者 : Ryan Apr 22,2026
Soul Strike X:泽尼亚第二季是一款高奇幻动作角色扮演游戏,战斗围绕精确的时机把握和强大的技能组合展开。鉴于各种角色和构建拥有大量可用的能力,识别表现最佳的技能对于成功至关重要。这些知识是征服 PvE 内容、击败挑战性首领以及在竞技 PvP 中攀升排名的关键。该游戏巧妙地将激烈的砍杀动作与深度的 RPG 机制及广泛的技能自定义相结合。无论你的目标是推进困难副本还是主宰 PvP 排行榜,这份梯队列表都将指导你的升级决策,以优化伤害输出和整体效能。此外,角色、同伴与宠物之间的协同作用能显著作者 : Ryan Apr 22,2026















![Taffy Tales [v1.07.3a]](https://imgs.ehr99.com/uploads/32/1719554710667e529623764.jpg)