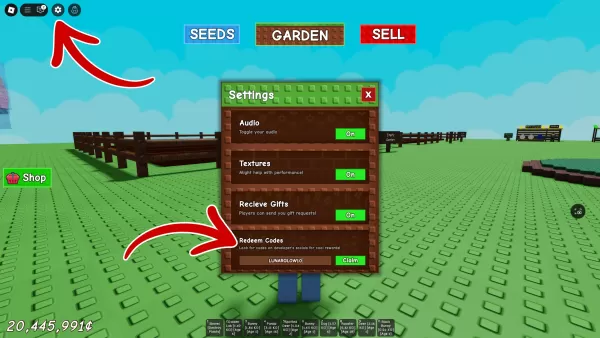
Chatgpt 제조업체는 중국의 흙 저렴한 expeek AI 모델이 OpenAI 데이터를 사용하여 구축되었다고 의심하며 인터넷에서 아이러니가 손실되지 않습니다.
Openai는 중국의 Deepseek AI 모델이 서구의 상대방보다 훨씬 저렴한 OpenAI의 데이터를 사용하여 훈련을 받았다고 의심합니다. 이 계시는 Deepseek의 인기가 급격히 증가함에 따라 주요 AI 회사의 극적인 시장 침체를 촉발 시켰습니다. AI 모델 개발에 중요한 GPU 기술의 핵심 업체 인 Nvidia는 최대 1 일 주식 손실을 경험하여 시장 가치가 거의 6 천억 달러를 잃었습니다. Microsoft, Meta 및 Alphabet과 같은 다른 기술 거인들도 상당한 감소를 겪었습니다.
Open-Source DeepSeek-V3을 기반으로 한 DeepSeek의 R1 모델은 서양 모델에 비해 교육 비용이 상당히 낮아지고 있습니다 (6 백만 달러). 이 주장은 일부 사람들에 의해 분쟁을 벌이고 있지만, 서구 기업들이 AI에있는 대규모 투자에 대한 우려를 불러 일으켰습니다. DeepSeek의 다운로드의 급증은 그 영향을 더욱 강조합니다.
OpenAi와 Microsoft는 DeepSeek이 API를 사용하거나 "증류"라는 기술을 사용하여 OpenAI의 서비스 약관을 위반했는지 여부를 조사하고 있습니다.이 기술은 더 큰 모델에서 데이터를 추출하여 작은 모델을 훈련시킵니다. Openai는 중국 기업들이 미국 AI 모델을 이끌고 적극적으로 재현하려고 시도하고 있으며 다양한 대책과 미국 정부와의 협력을 통해 지적 재산 (IP)을 보호하겠다는 약속을 강조합니다.
트럼프 대통령의 AI Czar 인 David Sacks는 데이터 추출 주장을지지하며 OpenAI는 미래의 증류 사례를 방지하기위한 조치를 이행 할 것이라고 제안합니다.
이 상황은 Chatgpt를 훈련시키기 위해 저작권이있는 자료를 사용한 자체의 역사를 고려할 때 Openai의 입장의 아이러니를 강조합니다. Openai는 이전에 저작권이없는 자료없이 오늘날의 주요 AI 모델을 만드는 것은 불가능하다고 주장했다. 영국의 하원에 제출 된 입장은 뉴욕 타임즈 (New York Times)와 저작권 침해를 주장하는 17 명의 저자의 소송에 의해 도전을받는 입장이다. Openai는 교육 관행이 "공정한 사용"을 구성한다고 주장합니다. AI 교육 데이터와 저작권을 둘러싼 법적 전투는 계속 전개되고 있으며, 2018 년 미국 저작권 사무소 판결은 "인간의 마음과 창조적 표현 사이의 넥서스"가 없기 때문에 AI 생성 예술은 저작권을받을 수 없다고 진술했습니다.

-
 Nikke는 6월 10일 메이저 리그 데뷔를 앞두고 있습니다. 스트리머 Emiru는 이 행사에 맞춰 Rapi로 코스프레할 예정입니다. 경기장에서는 제한된 기간 동안 다양한 이벤트가 펼쳐집니다. 승리의 여신: Nikke는 최근 야구를 모티브로 한 여름 업데이트를 론칭하며, 이제 진짜 야구장에 등장하게 되었습니다. 인기 있는 안드로이드 Noir 및 Blanc를 위한 스포티한 새 옷을 도입한 필드 데이 이벤트가 발표된 후, 이 과학소설 RPG는작가 : Aria Apr 16,2026
Nikke는 6월 10일 메이저 리그 데뷔를 앞두고 있습니다. 스트리머 Emiru는 이 행사에 맞춰 Rapi로 코스프레할 예정입니다. 경기장에서는 제한된 기간 동안 다양한 이벤트가 펼쳐집니다. 승리의 여신: Nikke는 최근 야구를 모티브로 한 여름 업데이트를 론칭하며, 이제 진짜 야구장에 등장하게 되었습니다. 인기 있는 안드로이드 Noir 및 Blanc를 위한 스포티한 새 옷을 도입한 필드 데이 이벤트가 발표된 후, 이 과학소설 RPG는작가 : Aria Apr 16,2026 -
 글로벌 페스트 이벤트는 10월 23일까지 계속됩니다.플레이어는 로그인만으로도 수많은 보상을 얻을 수 있습니다.업데이트에서는 새로운 캐릭터와 경쟁 토너먼트가 추가되었습니다.에테리아: 리스타트는 9월 업데이트 이후 동아시아 출시를 기념하기 위해 대규모 축제를 진행하고 있습니다. 이 글로벌 이벤트는 9월 25일부터 10월 23일까지 진행되며, 모든 서버의 플레이어들이 무료 보상, 신규 콘텐츠 및 치열한 경쟁에 참여할 수 있습니다.글로벌 페스트는 일반작가 : Nicholas Apr 16,2026
글로벌 페스트 이벤트는 10월 23일까지 계속됩니다.플레이어는 로그인만으로도 수많은 보상을 얻을 수 있습니다.업데이트에서는 새로운 캐릭터와 경쟁 토너먼트가 추가되었습니다.에테리아: 리스타트는 9월 업데이트 이후 동아시아 출시를 기념하기 위해 대규모 축제를 진행하고 있습니다. 이 글로벌 이벤트는 9월 25일부터 10월 23일까지 진행되며, 모든 서버의 플레이어들이 무료 보상, 신규 콘텐츠 및 치열한 경쟁에 참여할 수 있습니다.글로벌 페스트는 일반작가 : Nicholas Apr 16,2026












![Taffy Tales [v1.07.3a]](https://imgs.ehr99.com/uploads/32/1719554710667e529623764.jpg)