ChatGPT Maker Suspects China’s Dirt Cheap DeepSeek AI Models Were Built Using OpenAI Data — and the Irony Is Not Lost on the Internet
OpenAI suspects that China's DeepSeek AI models, significantly cheaper than Western counterparts, were trained using OpenAI's data. This revelation, coupled with DeepSeek's rapid rise in popularity, triggered a dramatic market downturn for major AI companies. Nvidia, a key player in GPU technology crucial for AI model development, experienced its largest-ever single-day stock loss, losing nearly $600 billion in market value. Other tech giants like Microsoft, Meta, and Alphabet also suffered significant declines.
DeepSeek's R1 model, based on the open-source DeepSeek-V3, boasts significantly lower training costs (estimated at $6 million) compared to Western models. While this claim is disputed by some, it has fueled concerns about the massive investments Western companies are making in AI. The surge in DeepSeek's downloads further underscores its impact.
OpenAI and Microsoft are investigating whether DeepSeek violated OpenAI's terms of service by using its API or employing a technique called "distillation" – extracting data from larger models to train smaller ones. OpenAI acknowledges that Chinese companies are actively attempting to replicate leading US AI models and emphasizes its commitment to protecting its intellectual property (IP) through various countermeasures and collaboration with the US government.
David Sacks, President Trump's AI czar, supports the claim of data extraction, suggesting that OpenAI will likely implement measures to prevent future instances of distillation.
This situation highlights the irony of OpenAI's position, given its own history of using copyrighted material to train ChatGPT. OpenAI has previously argued that creating today's leading AI models without copyrighted material is impossible, a stance supported by its submission to the UK's House of Lords and challenged by lawsuits from the New York Times and 17 authors alleging copyright infringement. OpenAI maintains that its training practices constitute "fair use." The legal battles surrounding AI training data and copyright continue to unfold, with a 2018 US Copyright Office ruling stating that AI-generated art cannot be copyrighted due to the lack of a "nexus between the human mind and creative expression."

-
 Nikke is set to make its Major League debut on June 10th.Streamer Emiru will be cosplaying as Rapi for the occasion.The stadium will feature a variety of limited-time activities.Goddess of Victory: Nikke recently swung into action with a baseball-insAuthor : Aria Apr 16,2026
Nikke is set to make its Major League debut on June 10th.Streamer Emiru will be cosplaying as Rapi for the occasion.The stadium will feature a variety of limited-time activities.Goddess of Victory: Nikke recently swung into action with a baseball-insAuthor : Aria Apr 16,2026 -
 The Global Fest event continues through October 23rd.Players can earn numerous rewards simply by logging in.The update introduces new characters and a competitive tournament.Etheria: Restart is launching a major celebration to mark its East Asia releAuthor : Nicholas Apr 16,2026
The Global Fest event continues through October 23rd.Players can earn numerous rewards simply by logging in.The update introduces new characters and a competitive tournament.Etheria: Restart is launching a major celebration to mark its East Asia releAuthor : Nicholas Apr 16,2026
-
 Flame of Valhalla GlobalDownload
Flame of Valhalla GlobalDownload -
 Indian Tractor Farming Sim 3DDownload
Indian Tractor Farming Sim 3DDownload -
 Royal Hotel: idle gameDownload
Royal Hotel: idle gameDownload -
 Rolling Ball Sky EscapeDownload
Rolling Ball Sky EscapeDownload -
 Ultimate SoccerDownload
Ultimate SoccerDownload -
 Murder Evidence Cleaner GamesDownload
Murder Evidence Cleaner GamesDownload -
 FantPlay11:Fantasy Cricket AppDownload
FantPlay11:Fantasy Cricket AppDownload -
 Avicii | Gravity HDDownload
Avicii | Gravity HDDownload -
 Antiyoy ClassicDownload
Antiyoy ClassicDownload -
 Match Puzzle - Shop MasterDownload
Match Puzzle - Shop MasterDownload





![Taffy Tales [v1.07.3a]](https://imgs.ehr99.com/uploads/32/1719554710667e529623764.jpg)



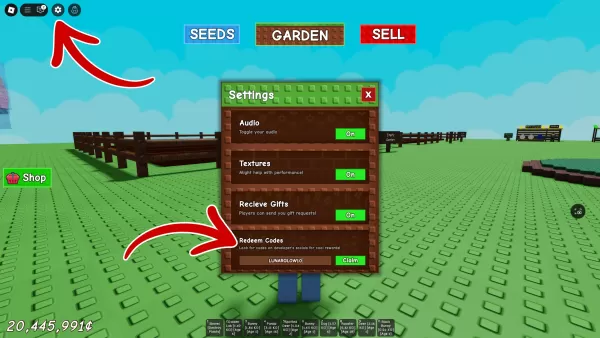

- Black Ops 6 Zombies: How To Configure The Summoning Circle Rings on Citadelle Des Morts
- Roblox: Latest DOORS Codes Released!
- Harvest Moon: Lost Valley DLC and Preorder Details Revealed
- Silent Hill 2 Remake Coming to Xbox and Switch in 2025
- Roblox: Blox Fruits Codes (January 2025)
- Roblox: Freeze for UGC Codes (January 2025)