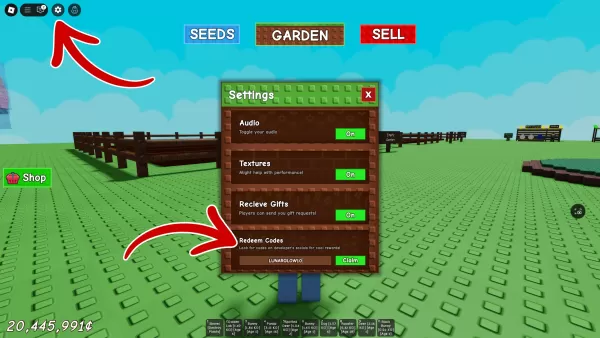
Chatgpt Maker怀疑中国的污垢廉价DeepSeek AI模型是使用OpenAI数据建造的,而具有讽刺意味
Openai怀疑使用OpenAI的数据对中国的DeepSeek AI模型(比西方同行便宜得多)进行了培训。这种启示,加上Deepseek的迅速流行,引发了大型AI公司的巨大市场经济衰退。 NVIDIA是AI模型开发至关重要的GPU技术的关键参与者,经历了其有史以来最大的单日股票损失,损失了近6000亿美元的市场价值。 Microsoft,Meta和Alphabet等其他科技巨头也有显着下降。
与西方模型相比,DeepSeek的R1模型基于开源DeepSeek-V3的培训成本(估计为600万美元)。尽管某些人提出了这一主张,但它引起了人们对西方公司在AI的大规模投资的担忧。 DeepSeek下载的激增进一步强调了其影响。
Openai和Microsoft正在调查DeepSeek是否通过使用其API或采用一种称为“蒸馏”的技术来违反OpenAI的服务条款 - 从较大型号中提取数据来培训较小的模型。 Openai承认,中国公司正在积极试图复制领导美国AI模型,并强调其致力于通过各种对策和与美国政府合作保护其知识产权(IP)的承诺。
特朗普总统的AI沙皇戴维·萨克斯(David Sacks)支持数据提取的主张,这表明OpenAI可能会采取措施,以防止将来的蒸馏实例。
鉴于其自己使用受版权保护的材料训练Chatgpt的历史,这种情况凸显了Openai立场的讽刺意味。 Openai此前曾认为,创建当今未经版权材料的当今领先的AI模型是不可能的,这一立场支持了其向英国上议院提交的支持,并受到《纽约时报》和17位指控侵犯版权的诉讼的挑战。 Openai坚持认为其培训实践构成“合理使用”。围绕AI培训数据和版权的法律斗争继续展开,2018年美国版权局裁定表示,由于“人类思维和创造性表达之间的联系”,AI基础的艺术无法获得版权。

-
 尼基即将在6月10日迎来其大联盟首秀。流媒体主播埃米尔将在此次活动中扮演瑞比。体育场将举办各种限时活动。胜利女神:尼基最近推出了以棒球为主题的夏季更新,现在它将走上现实中的棒球场。随着“Field Day”活动的推出,该科幻RPG游戏正在为它的大联盟首秀做准备。此次活动将于6月10日在圣地亚哥教士队对阵洛杉矶道奇队的比赛期间在Petco公园举行。晚上将从一个特别的第一球仪式开始,由知名coser和主播埃米尔扮演的《胜利女神:尼基》中的瑞比进行投球。她还将与其他官方尼基coser一同参加粉丝见面会作者 : Aria Apr 16,2026
尼基即将在6月10日迎来其大联盟首秀。流媒体主播埃米尔将在此次活动中扮演瑞比。体育场将举办各种限时活动。胜利女神:尼基最近推出了以棒球为主题的夏季更新,现在它将走上现实中的棒球场。随着“Field Day”活动的推出,该科幻RPG游戏正在为它的大联盟首秀做准备。此次活动将于6月10日在圣地亚哥教士队对阵洛杉矶道奇队的比赛期间在Petco公园举行。晚上将从一个特别的第一球仪式开始,由知名coser和主播埃米尔扮演的《胜利女神:尼基》中的瑞比进行投球。她还将与其他官方尼基coser一同参加粉丝见面会作者 : Aria Apr 16,2026 -
 全球庆典活动将持续至10月23日。玩家只需登录即可获得大量奖励。此次更新引入了新角色和竞技比赛。《Etheria: Restart》在九月份的更新后,为纪念其东亚地区的发布,将举行盛大的庆祝活动。这次全球活动从9月25日持续至10月23日,所有服务器的玩家均可参与,享受免费奖励、新鲜内容以及激烈的竞赛。Global Fest不仅仅是一次普通的庆典。只需登录即可获得奖励,包括使用代码ETHERIA0925可获得10次免费召唤,还有一个7天的登录活动,将赠送包含如莉莉等受欢迎英雄的高级光暗SSR选择作者 : Nicholas Apr 16,2026
全球庆典活动将持续至10月23日。玩家只需登录即可获得大量奖励。此次更新引入了新角色和竞技比赛。《Etheria: Restart》在九月份的更新后,为纪念其东亚地区的发布,将举行盛大的庆祝活动。这次全球活动从9月25日持续至10月23日,所有服务器的玩家均可参与,享受免费奖励、新鲜内容以及激烈的竞赛。Global Fest不仅仅是一次普通的庆典。只需登录即可获得奖励,包括使用代码ETHERIA0925可获得10次免费召唤,还有一个7天的登录活动,将赠送包含如莉莉等受欢迎英雄的高级光暗SSR选择作者 : Nicholas Apr 16,2026












![Taffy Tales [v1.07.3a]](https://imgs.ehr99.com/uploads/32/1719554710667e529623764.jpg)