CHATGPT मेकर को संदेह है कि चीन की गंदगी सस्ते डीपसेक एआई मॉडल ओपनईएआई डेटा का उपयोग करके बनाया गया था - और विडंबना इंटरनेट पर खो नहीं है
Openai को संदेह है कि चीन के डीपसेक AI मॉडल, पश्चिमी समकक्षों की तुलना में काफी सस्ते, Openai के डेटा का उपयोग करके प्रशिक्षित किए गए थे। यह रहस्योद्घाटन, डीपसेक की लोकप्रियता में तेजी से वृद्धि के साथ मिलकर, प्रमुख एआई कंपनियों के लिए एक नाटकीय बाजार मंदी को ट्रिगर किया। एनवीडिया, जीपीयू प्रौद्योगिकी में एक प्रमुख खिलाड़ी, एआई मॉडल विकास के लिए महत्वपूर्ण है, ने अपने सबसे बड़े एकल-दिन स्टॉक हानि का अनुभव किया, जो बाजार मूल्य में लगभग $ 600 बिलियन का नुकसान हुआ। Microsoft, मेटा और अल्फाबेट जैसे अन्य तकनीकी दिग्गजों को भी महत्वपूर्ण गिरावट का सामना करना पड़ा।
ओपन-सोर्स डीपसेक-वी 3 पर आधारित दीपसेक का आर 1 मॉडल, पश्चिमी मॉडल की तुलना में काफी कम प्रशिक्षण लागत ($ 6 मिलियन में अनुमानित) का दावा करता है। जबकि यह दावा कुछ लोगों द्वारा विवादित है, इसने एआई में पश्चिमी कंपनियों के बड़े पैमाने पर निवेश करने के बारे में चिंताओं को पूरा किया है। दीपसेक के डाउनलोड में उछाल इसके प्रभाव को और अधिक रेखांकित करता है।
Openai और Microsoft यह जांच कर रहे हैं कि क्या DeePseek ने अपने API का उपयोग करके Openai की सेवा की शर्तों का उल्लंघन किया है या "डिस्टिलेशन" नामक एक तकनीक को नियोजित करके - छोटे से प्रशिक्षित करने के लिए बड़े मॉडल से डेटा निकालना। Openai स्वीकार करता है कि चीनी कंपनियां सक्रिय रूप से अमेरिकी AI मॉडल को दोहराने का प्रयास कर रही हैं और विभिन्न काउंटरमेशर्स और अमेरिकी सरकार के साथ सहयोग के माध्यम से अपनी बौद्धिक संपदा (IP) की रक्षा के लिए अपनी प्रतिबद्धता पर जोर देती हैं।
डेविड सैक्स, राष्ट्रपति ट्रम्प के एआई सीज़र, डेटा निष्कर्षण के दावे का समर्थन करते हैं, यह सुझाव देते हुए कि Openai संभवतः भविष्य के आसवन के उदाहरणों को रोकने के उपायों को लागू करेगा।
यह स्थिति Openai की स्थिति की विडंबना को उजागर करती है, जिसे Chatgpt को प्रशिक्षित करने के लिए कॉपीराइट सामग्री का उपयोग करने का अपना इतिहास दिया गया है। Openai ने पहले तर्क दिया है कि कॉपीराइट सामग्री के बिना आज के अग्रणी AI मॉडल बनाना असंभव है, एक रुख यूके के हाउस ऑफ लॉर्ड्स को प्रस्तुत करने और न्यूयॉर्क टाइम्स के मुकदमों द्वारा चुनौती देने और 17 लेखकों को कॉपीराइट उल्लंघन का आरोप लगाने के लिए चुनौती देता है। Openai का कहना है कि इसके प्रशिक्षण प्रथाओं "उचित उपयोग" का गठन करती है। एआई प्रशिक्षण डेटा और कॉपीराइट के आसपास की कानूनी लड़ाई जारी है, 2018 के अमेरिकी कॉपीराइट कार्यालय सत्तारूढ़ के साथ यह कहते हुए कि एआई-जनित कला को "मानव मन और रचनात्मक अभिव्यक्ति के बीच नेक्सस" की कमी के कारण कॉपीराइट नहीं किया जा सकता है।

-
डिज़नी ने टॉय स्टोरी 5 में एक महत्वपूर्ण भूमिका के लिए आधिकारिक तौर पर कॉनन ओ'ब्रायन की पुष्टि की है। करिश्माई टॉक शो होस्ट स्मार्टी पैंट नामक एक रहस्यमय नए चरित्र को अपनी आवाज देगा, जो पहली बार प्रतिष्ठित फ्रैंचाइज़ी के लिए एक नए जोड़ को चिह्नित करता है। अपने अधिकारी पर एक विनोदी पोस्ट मेंलेखक : Aurora Jun 04,2025
-
 विंडरिडर ओरिजिन के लिए अल्टीमेट रेड डंगऑन गाइड में आपका स्वागत है, फंतासी एक्शन आरपीजी जो आपको जादू, राक्षसों और महाकाव्य लड़ाई की दुनिया में डुबो देता है। जैसा कि आप खेल के माध्यम से यात्रा करते हैं, आप छापे के काल कोठरी का सामना करेंगे- इंटेंस, उच्च-स्तरीय चुनौतियों का सामना करने योग्य मालिकों और शीर्ष-स्तरीय पुरस्कारों की विशेषता।लेखक : Layla Jun 04,2025
विंडरिडर ओरिजिन के लिए अल्टीमेट रेड डंगऑन गाइड में आपका स्वागत है, फंतासी एक्शन आरपीजी जो आपको जादू, राक्षसों और महाकाव्य लड़ाई की दुनिया में डुबो देता है। जैसा कि आप खेल के माध्यम से यात्रा करते हैं, आप छापे के काल कोठरी का सामना करेंगे- इंटेंस, उच्च-स्तरीय चुनौतियों का सामना करने योग्य मालिकों और शीर्ष-स्तरीय पुरस्कारों की विशेषता।लेखक : Layla Jun 04,2025
-
 Inca Treasure Slots – Freeडाउनलोड करना
Inca Treasure Slots – Freeडाउनलोड करना -
 Deams of Realityडाउनलोड करना
Deams of Realityडाउनलोड करना -
 Indian Street Food Recipesडाउनलोड करना
Indian Street Food Recipesडाउनलोड करना -
 Transport Cruise Ship Gamesडाउनलोड करना
Transport Cruise Ship Gamesडाउनलोड करना -
 LordsWM Mobileडाउनलोड करना
LordsWM Mobileडाउनलोड करना -
 SlotMan - Free Classic Vegas Slot Machine 777डाउनलोड करना
SlotMan - Free Classic Vegas Slot Machine 777डाउनलोड करना -
 Jackpot Games Roomडाउनलोड करना
Jackpot Games Roomडाउनलोड करना -
 Top slotsडाउनलोड करना
Top slotsडाउनलोड करना -
 Fan Quiz for NBAडाउनलोड करना
Fan Quiz for NBAडाउनलोड करना -
 DR!FTडाउनलोड करना
DR!FTडाउनलोड करना





![Taffy Tales [v1.07.3a]](https://imgs.ehr99.com/uploads/32/1719554710667e529623764.jpg)



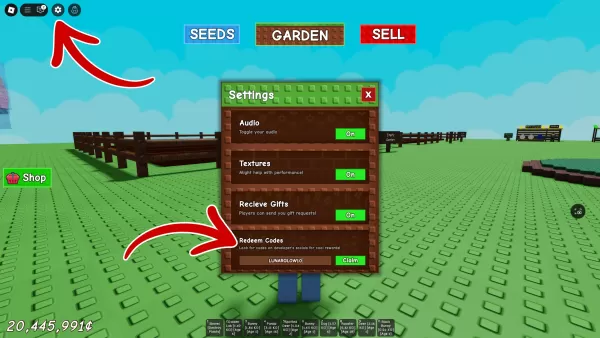

- हार्वेस्ट मून: लॉस्ट वैली डीएलसी और प्रीऑर्डर विवरण प्रकट हुआ
- ब्लैक ऑप्स 6 जॉम्बीज: सिटाडेल डेस मोर्ट्स पर सममनिंग सर्कल रिंग्स को कैसे कॉन्फ़िगर करें
- Roblox: नवीनतम डोर्स कोड जारी!
- Roblox: ब्लॉक्स फ्रूट्स कोड (जनवरी 2025)
- Roblox: यूजीसी कोड के लिए रोक (जनवरी 2025)
- साइलेंट हिल 2 का रीमेक Xbox आ रहा है और 2025 में स्विच किया जाएगा